Guía completa para probar tus copilotos personalizados utilizando Power CAT Copilot Studio Kit, una herramienta diseñada para mejorar las capacidades de Microsoft Copilot Studio.
El Microsoft Power Customer Advisory Team (Power CAT) lanzó hace ya unos meses una nueva herramienta llamada Power CAT Copilot Studio Kit1, que es un amplio conjunto de herramientas diseñadas para mejorar las capacidades de Microsoft Copilot Studio. El kit incluye una variedad de herramientas que nos permiten someter a nuestros copilotos personalizados a algunos escenarios de prueba, asegurándonos de que funcionan como se espera en aplicaciones en producción.
Este artículo te guiará por los pasos necesarios para empezar a probar tus copilotos personalizados utilizando esta innovadora herramienta.
Conceptos básicos
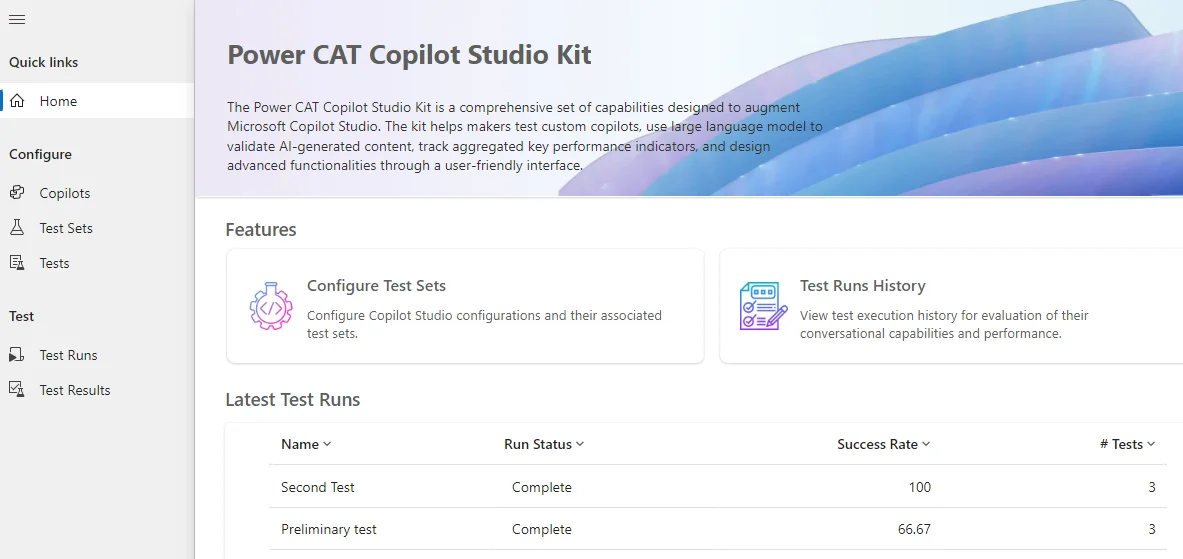
Después de instalar el kit (comprueba primero los requisitos previos), puedes ejecutar la model-driven app Copilot Studio Kit, que actualmente muestra las siguientes opciones:
Copilotos: Información básica del copiloto personalizado que quieres probar.
Pruebas: Pruebas unitarias sobre el copiloto. Dichas pruebas pueden ser de cualquiera de los siguientes tipos: Coincidencia de respuesta, Adjuntos, Coincidencia de tema y Respuestas generativas.
Conjuntos de Pruebas: Permite crear un grupo de pruebas unitarias.
Pruebas ejecutadas: Lista de todas las pruebas que se han ejecutado.
Resultados de las pruebas: Lista de todos los resultados de las pruebas.
Puedes ver este excelente vídeo2 de Dewain Robinson, de Microsoft, sobre qué es Copilot Studio Kit, cómo instalarlo y cómo crear una prueba muy básica.
Una de las funciones más destacadas es la herramienta de validación de Large Language Model (LLM). Esta función comprueba la precisión y coherencia de los contenidos generados por la IA y te da la seguridad de que los resultados de tu copiloto cumplen las normas de calidad y conformidad. Es como tener un par de ojos extra, siempre asegurándose de que el contenido producido es de calidad y adecuado en el contexto de la conversación.
A continuación, vamos a demostrar paso a paso, cómo configurar y ejecutar pruebas en un copiloto existente.
Configuración de la prueba
En la sección de Copilotos tenemos que introducir una serie de parámetros sobre el copiloto que queremos probar:
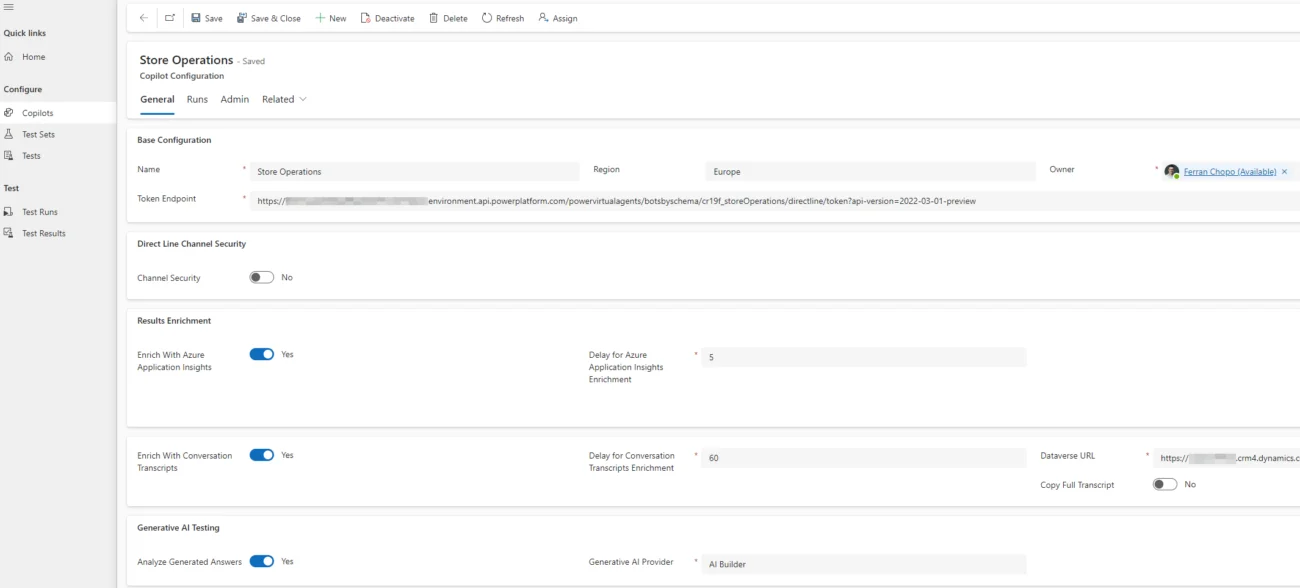
Configuración base: Nombre, Región y Token Endpoint del copiloto. Puedes leer el siguiente artículo3 sobre cómo obtener la URL del Token Endpoint, mientras que la Región depende de la ubicación del entorno donde desplegaste (publicaste) el copiloto.
Seguridad del canal Direct Line: Si está habilitado (porque tu copiloto está publicado en un sitio web, y quieres restringir quién puede acceder a él), puedes configurar dónde almacenar el secreto del canal. En nuestro caso, sólo hemos publicado el chatbot en Teams, por lo que no es necesario configurarlo.
Enriquecimiento de resultados: Recomendado para probar los resultados de Generative Answers utilizando los datos de Application Insights. Utilizamos los valores recomendados para todos los campos y también configuramos la URL de Dataverse (entorno).
Prueba de IA Generativa: Definimos qué LLM queremos utilizar para probar Generative Answers. Actualmente AI Builder es el único proveedor de IA Generativa disponible para seleccionar.
Queremos probar un copiloto llamado Store Operations, y la sección de configuración sería la siguiente:
Creación de las pruebas
En la sección de pruebas podemos crear diferentes tipos de éstas como ya indicamos anteriormente. Vamos a crear una de cada tipo:
Prueba Response Match
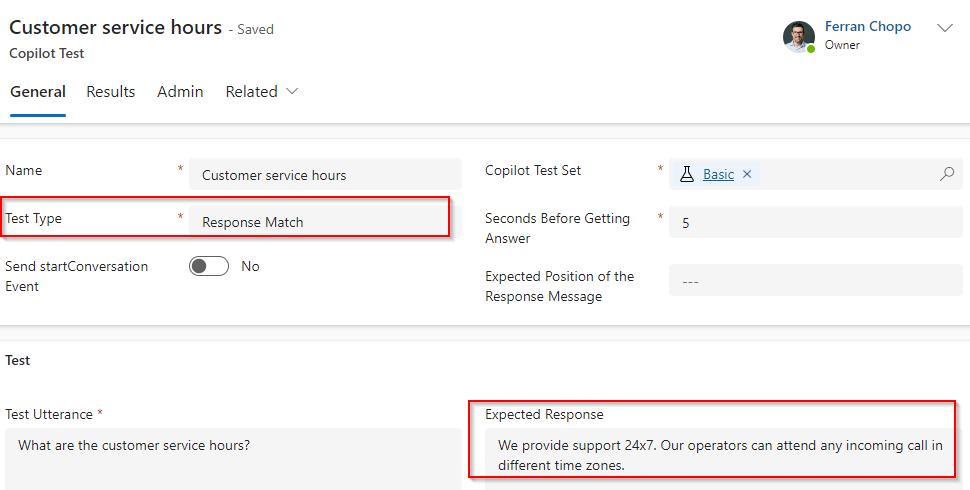
Se trata de la prueba más fácil de configurar, ya que queremos comprobar que, dado un enunciado (pregunta), el copiloto devuelve la respuesta esperada (y fija). Como en otras pruebas, tenemos que configurar atributos como el nombre o el conjunto de pruebas, pero los más importantes son los siguientes:
Segundos antes de obtener la respuesta: La latencia en devolver una respuesta puede variar en función de diferentes factores. Si no estamos seguros, Microsoft recomienda poner 10 segundos y ajustar en función de nuestros resultados.
Enunciado: Pregunta o texto a enviar al copiloto.
Respuesta esperada: Valor que se espera que devuelva el copiloto cuando se le envíe el enunciado de prueba.
El copiloto que estamos probando debe devolver siempre la misma respuesta cuando los usuarios preguntan por los horarios de atención al cliente, por lo que podemos utilizar una prueba de Response Match:
También podríamos iniciar la prueba enviando un evento startConversation, que activará el tema Greeting, aunque en este caso no lo necesitamos.
Prueba Topic Match
¿Y si queremos comprobar qué temas se activarán en función del enunciado enviado por el usuario? De eso trata esta prueba: compara el nombre del tema esperado con el del tema activado (al configurar el copiloto, recuerde activar la opción Enrich with Conversation Transcripts).
Hemos creado un tema en nuestro copiloto llamado Track order, que gestiona el estado de un pedido:
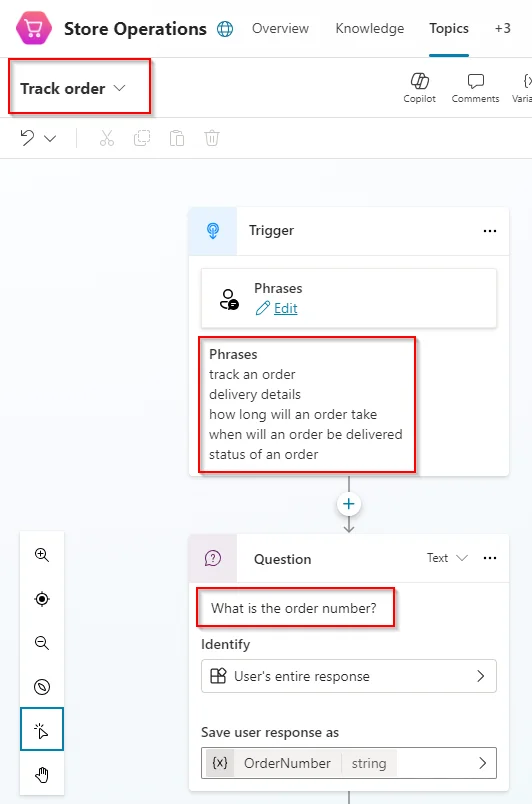
Este tema debe activarse cada vez que el usuario escriba frases como seguimiento de un pedido o detalles de entrega, y el copiloto le hará una pregunta: ¿Cuál es el número de pedido? Por lo tanto, podríamos escribir una prueba como el que mostramos en la siguiente imagen:
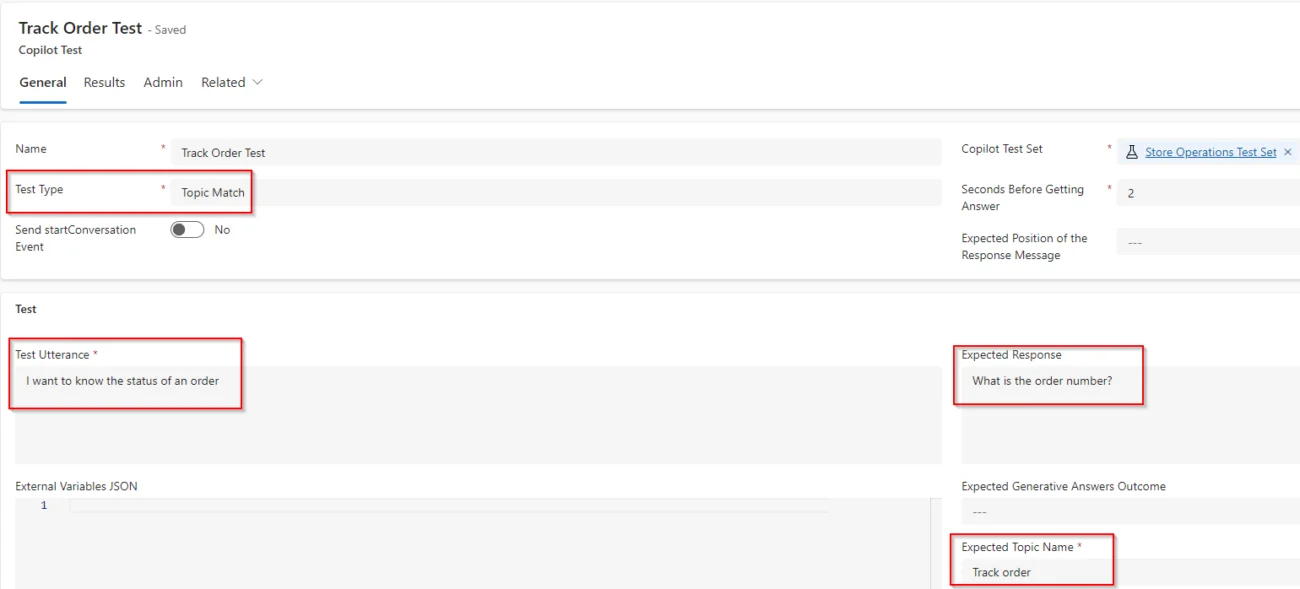
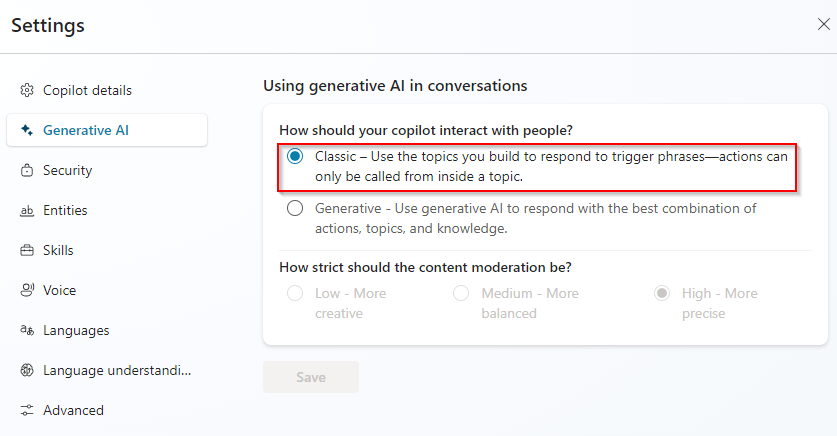
En este caso utilizamos los mismos atributos que en la prueba de Response Match y también definimos el valor para el atributo Expected Topic Name. Es importante señalar que, en este caso, estamos utilizando el enfoque clásico en el uso de IA generativa en las conversaciones. Esto significa que estamos usando temas que construimos para responder a frases disparadoras (triggers), y no usando IA generativa para determinar el mejor tema para disparar (lo que conocemos en el pasado como dynamic chaining). Esto puede configurarse en los ajustes del copiloto y cambiarse en cualquier momento.
Prueba de Generative Answers
En nuestro copiloto estamos usando dos sitios web públicos para responder a preguntas sobre algunos dispositivos y sobre información de facturación, como podemos ver en la siguiente imagen:
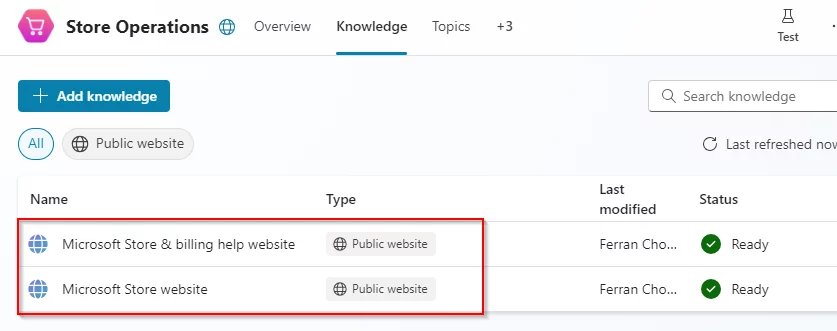
Cuando un usuario envía una consulta y el copiloto no puede encontrar una coincidencia con los distintos temas, se activa el tema Conversational Boosting (siempre que esté activada la opción Permitir que la IA utilice sus propios conocimientos generales (vista previa)). Si esta opción está desactivada, el tema del sistema activado será el conocido como Fallback. ¿Qué sucederá si queremos probar una respuesta cuando el usuario hace una pregunta relativa a un dispositivo de Microsoft? Nuestro copiloto puede usar el sito de Microsoft Store para devolver la información que allí se encuentra. Vamos a probarlo con la siguiente prueba:
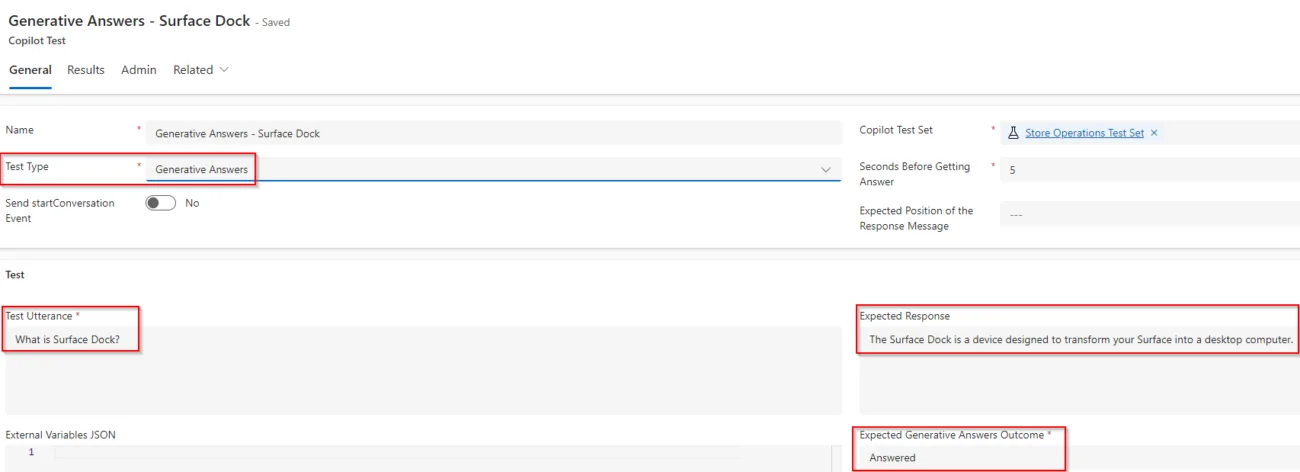
Los atributos más importantes para configurar en este caso son:
Respuesta esperada: La respuesta no es determinista - si la información del sitio web de Microsoft se actualiza, o el LLM utilizado en Copilot Studio también se actualiza, la respuesta a la misma consulta puede ser diferente. Como resultado, establecemos un valor que debería ser similar a lo que esperamos como respuesta.
Resultado esperado de las respuestas generativas: Dependiendo del enunciado y de las fuentes de conocimiento que estemos utilizando, esperamos que el resultado sea respondido o no respondido.
En este caso, la herramienta va a utilizar AI Builder como proveedor de IA Generativa y comprobará si la respuesta generada por la IA se aproxima a las respuestas de muestra o cumple las instrucciones de validación. Es importante tener en cuenta que, para ejecutar este tipo de pruebas, necesitamos habilitar la opción de Generative AI Testing en la configuración del copiloto.
Prueba de Attachments (Adaptive Cards)
Gracias a las Adaptive Cards, un copiloto puede presentar los resultados de las consultas de forma más fácil y clara. Al aprovecharlas, un copiloto puede mostrar la información en un formato estructurado, lo que facilita a los usuarios la comprensión de los datos y la interacción con ellos. ¿No sería fantástico poder probar también resultados que muestren la información utilizando este formato?
Dentro de nuestro copiloto hemos creado un tema para devolver información sobre ordenadores portátiles específicos que están almacenados en una tabla en Dataverse. La información sobre el portátil se muestra utilizando una tarjeta adaptable, y la prueba se configuraría de la forma siguiente:
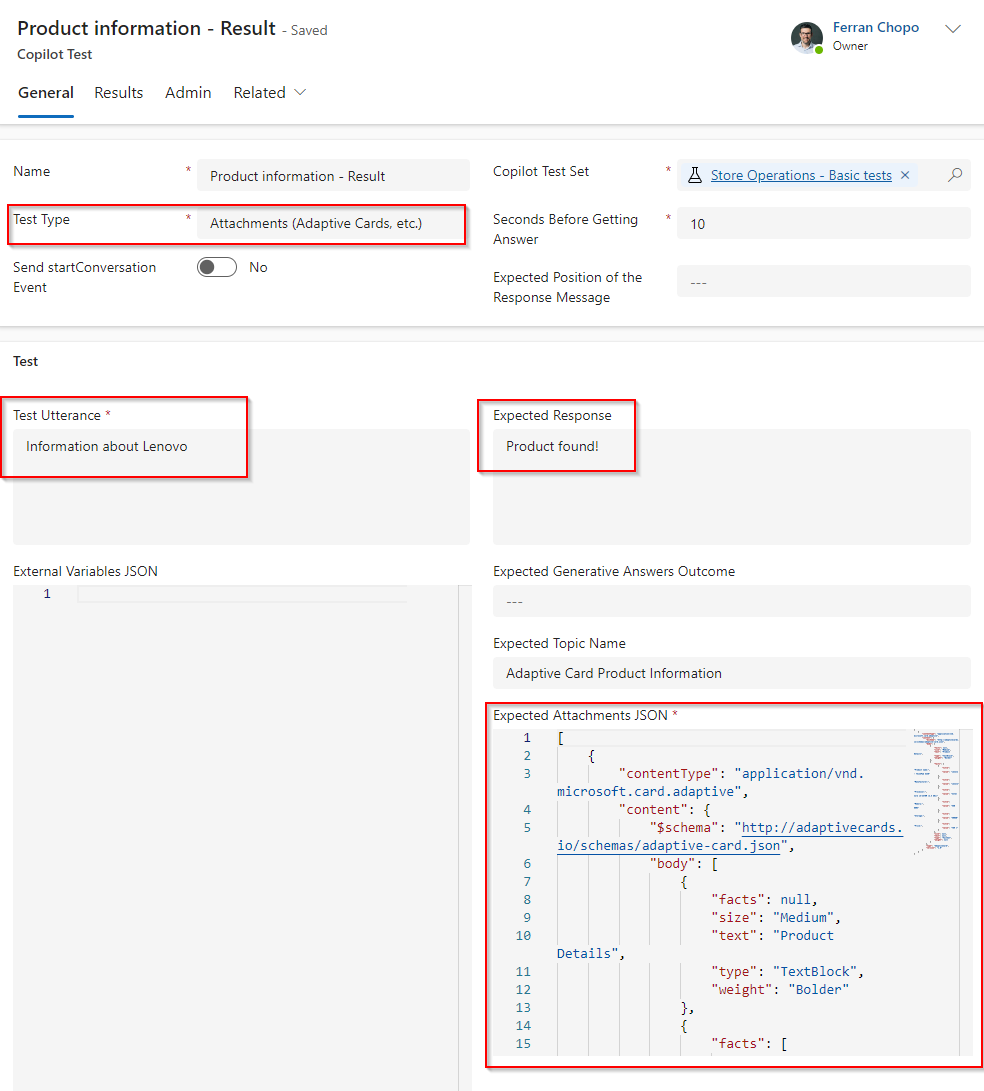
Ahora que ya hemos configurado los diferentes tipos de prueba, vamos a ponerlos todos juntos en un conjunto de pruebas (Tests Sets).
Creación del conjunto de pruebas
Un conjunto de pruebas es una colección de varias pruebas agrupadas. Esto nos permite ejecutar todas las pruebas del conjunto simultáneamente, lo que facilita la evaluación del rendimiento y la precisión del copiloto. Al final, al organizar las pruebas en conjuntos, puedes gestionar y ejecutar de forma eficaz escenarios de pruebas completos, asegurándote de que tu copiloto funciona como se espera en diversas situaciones.
Cuando creamos las pruebas, es necesario asignarlas a un conjunto de pruebas de copiloto específico. Por lo tanto, tenemos dos opciones para crear un conjunto de pruebas:
Crearla desde la sección Test Sets.
Creare desde la pantalla New Test.
Debemos tener presente que, si eliminamos un conjunto de pruebas, eliminamos todas las pruebas que contiene. Hemos creado un conjunto de pruebas que tiene un test de cada tipo, y que tendría el siguiente aspecto:
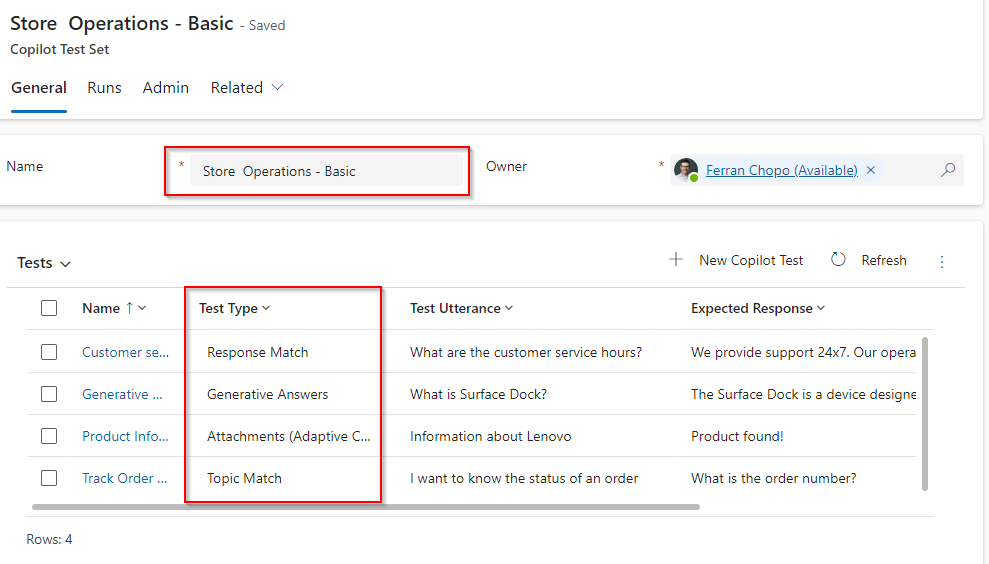
Evidentemente podemos crear otros conjuntos de prueba que contengan combinaciones de pruebas existentes.
Creación de Test Runs
Desde la sección Test Runs podemos crear ejecuciones de prueba, que principalmente se basa en seleccionar un conjunto de pruebas y a la configuración del copiloto. Cuando acabamos de crear la ejecución, todas las pruebas empiezan a ejecutarse y desde la pantalla principal podemos ver el resultado para cada una de ellas y ver los detalles de estas:
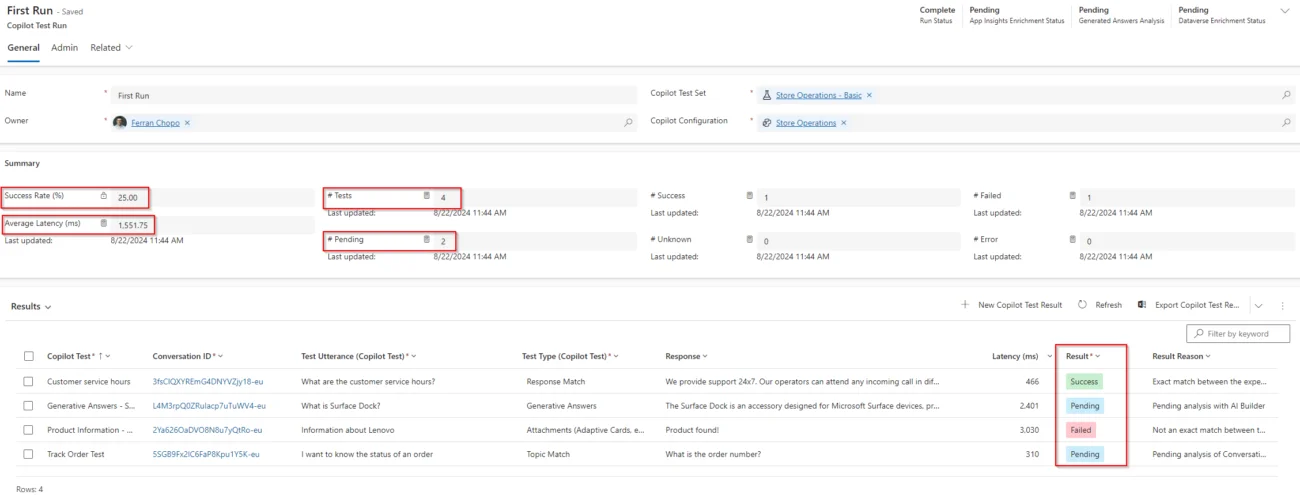
Algunos tipos de pruebas, como las Generative Answers o Topic Match pueden tardar algún tiempo en ejecutarse, como podemos ver en la captura de pantalla anterior. En el primer caso, AI Builder está generando una respuesta para compararla con la esperada, mientras que el segundo está pendiente porque hay que analizar la transcripción de la conversación.
Análisis de los resultados
Si queremos analizar los resultados de cada prueba, podemos entrar en la sección Resultados de la prueba y, a continuación, recorrer la pantalla de detalles de cada resultado de la prueba. Además del atributo Resultado, también podemos comprobar cuál fue el Topic disparado, la latencia y el motivo del resultado.
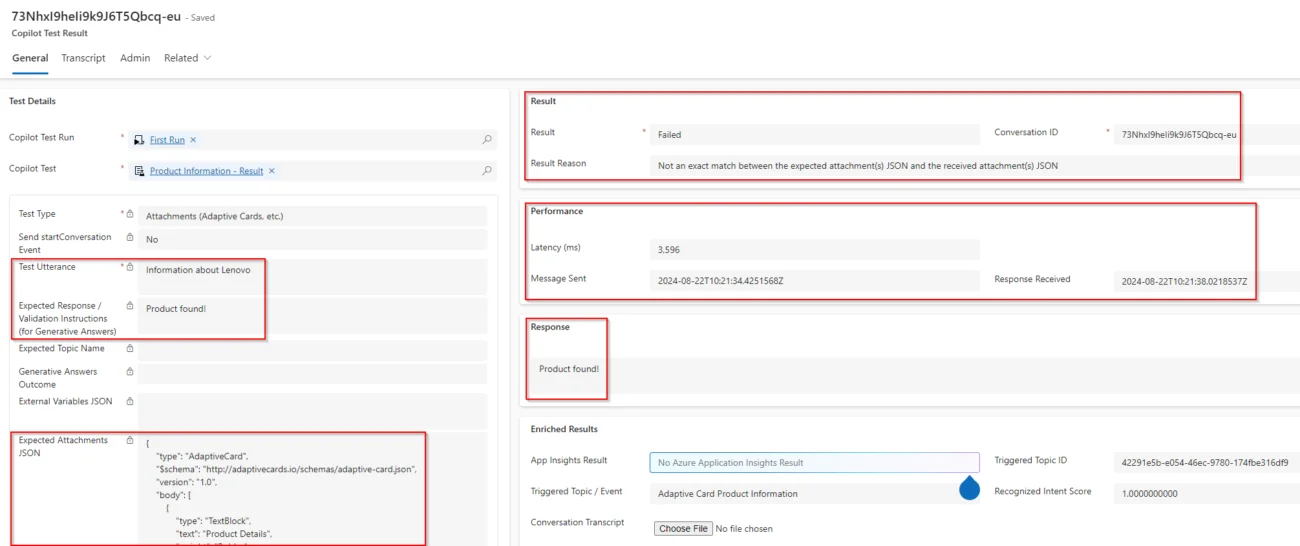
Como se menciona en la documentación oficial4, algunas pruebas pueden tardar algún tiempo en completarse. Por ejemplo, las pruebas de Topic Match se basan en la configuración del copiloto Dataverse Enrichment, qué en nuestro caso está configurado para retrasarse 60 minutos antes de iniciar el análisis (valor recomendado por Microsoft).
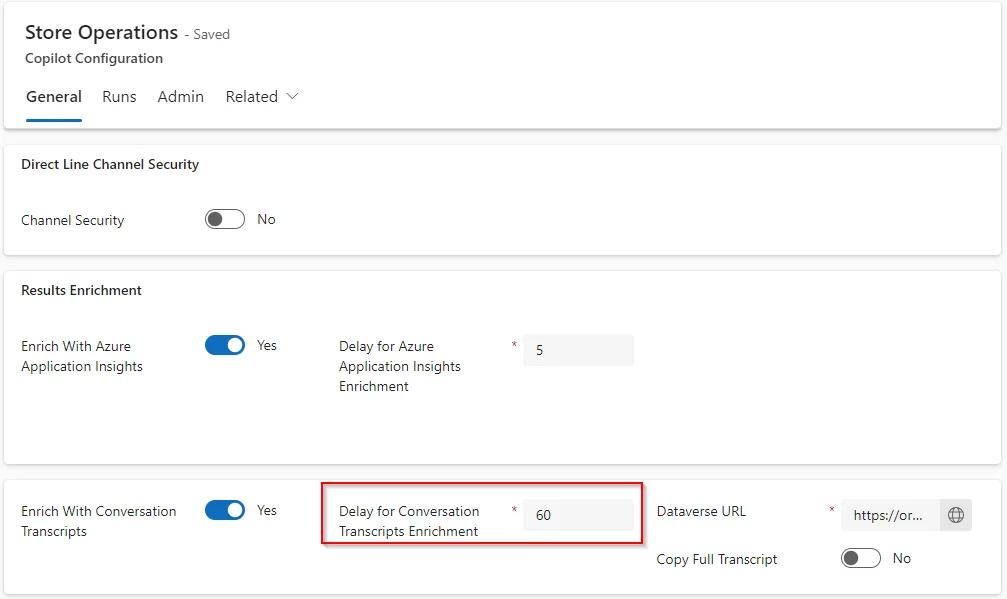
Si activamos la opción Copy Full Transcript, esta transcripción también se almacenará en los detalles de resultados de cada prueba, lo que puede proporcionar información realmente útil, pero al mismo tiempo, necesitaremos más almacenamiento en Dataverse.
Volver a ejecutar las pruebas
En algunos casos podría ser muy útil ejecutar sólo algunas pruebas específicas dentro de un Test Set. El Copilot Studio Kit está almacenado en una solución en nuestro entorno, que podemos inspeccionar libremente. Así, podemos comprobar que cuando ejecutamos una prueba, se ejecuta un flujo de Power Automate llamado Run Copilot Tests. Al mismo tiempo, este flujo llama a 4 flujos hijos diferentes, que son los siguientes:
Enrich with App Insights: Las pruebas de respuestas generativas utilizan Application Insights y AI Builder. Más concretamente, este flujo ejecutará una consulta analítica para encontrar eventos relacionados con respuestas generativas en Application Insights para la conversación probada y, después, activará el flujo Analyse with AI Builder.
Analyse with AI Builder: Todas las pruebas de tipo Generative Answers se ejecutarán ejecutando este flujo, utilizando AI Builder para obtener una respuesta (utilizando un LLM) y comparándola con el resultado esperado.
Enrich with Dataverse: Todas las pruebas de tipo Topic Match necesitan acceder a las transcripciones de las conversaciones almacenadas en Dataverse. Este flujo en la nube comprobará que existe una coincidencia entre el topic disparado en una prueba con el esperado.
Update Rollup columns: Flujo para actualizar columnas de resultados de ejecuciones de pruebas como número de pruebas con éxito, pruebas fallidas, latencia media, etc.
Podemos ejecutar cualquiera de estos flujos desde la pantalla Test Runs:
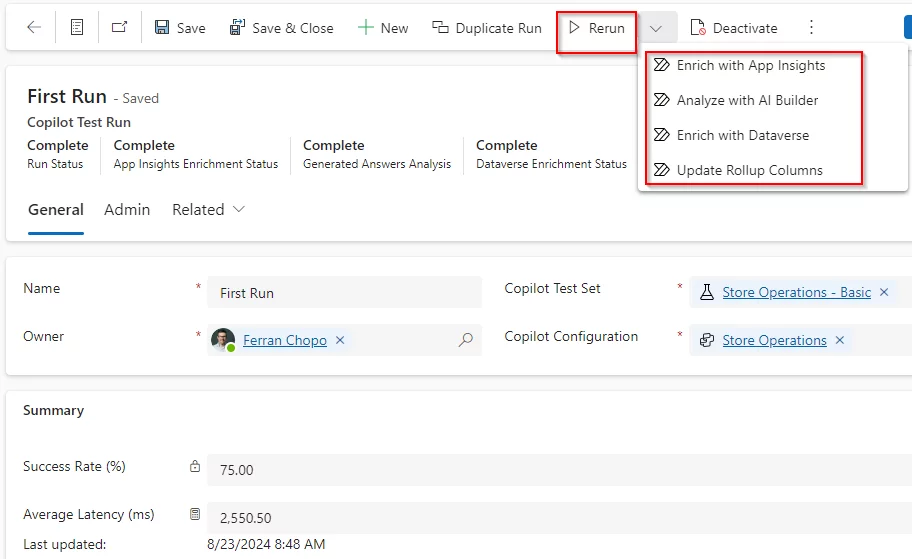
Si queremos ejecutar todas las pruebas de nuevo, en lugar de utilizar los flujos individualmente, podemos utilizar la opción Duplicate Run. De esta forma, una nueva ejecución de pruebas se creará con nuevas estadísticas.
Conclusiones
Como ya os habréis dado cuenta, probar los copilotos es esencial (especialmente cuando se utilizan respuestas generativas) para garantizar la precisión, la fiabilidad y, en definitiva, ganarnos la confianza del usuario al usarlos. El Copilot Studio Kit constituye una base excelente para este proceso, ya que ofrece herramientas que facilitan la realización de pruebas exhaustivas y el perfeccionamiento. Su interfaz fácil de usar lo convierte en una opción excelente para las fases de prueba iniciales.
Sin embargo, cuando se trata de escenarios más complejos, las pruebas manuales siguen siendo indispensables para obtener resultados completos y precisos. Este enfoque combinado aprovecha los puntos fuertes tanto de las pruebas automatizadas como de las manuales, lo que en última instancia conduce a unos copilotos más fiables y eficaces.
Ahora solo nos falta esperar que las próximas versiones de estas herramientas incorporen nuevas funciones que nos permitan crear pruebas más complejas.
Ferran Chopo MVP Business Apps | MCT https://www.linkedin.com/in/fchopo/
https://github.com/microsoft/Power-CAT-Copilot-Studio-Kit ↩︎
https://learn.microsoft.com/es-es/microsoft-copilot-studio/publication-connect-bot-to-custom-application#retrieve-your-copilot-studio-copilot-parameters ↩︎
https://github.com/microsoft/Power-CAT-Copilot-Studio-Kit/blob/main/RUN_TESTS.md#understanding-what-happens-when-a-test-runs ↩︎
De la revista Revista CompartiMOSS Nº 62
Edición especial dedicada a Microsoft 365 y las últimas innovaciones en productividad empresarial.
Ver más artículos de esta revista →